OTel Profiling 技术发展介绍
OTel Profiling 简介
OTel 社区从 2022 年在 KubeCon + CloudNativeCon Europe 2022 in Valencia 大会开始关注 Profiling 领域的建设,在那次的会议上成立了 Profiling SIG,这个兴趣小组成为了后续推动 OTel 在 Profiling 方面建设发展的主要推动力量。该 SIG 的主要活跃贡献者目前主要来自于 Grafana Labs、Elastic、Red Hat 以及 DataDog 等。
Profiling SIG 资料
OTel Profiling 演进介绍
下图展示了OTel Profiling发展过程中的一些关键节点:

2024年以来,OTel Profiling 发展很快,完成了包括新版 Data model 设计、Data model 合入 OTel社区Spec、基于 Spec 开发对应实现等工作。接下来,结合OTel社区的Spec发起流程,介绍上述相关时间节点细节:
OpenTelemetry 项目对一种新数据类型的支持过程分为以下步骤:
编写并向社区提交 OpenTelemetry Enhancement Proposal(OTEP)。OpenTelemetry OTEP 旨在进行跨领域的变更(即跨语言和实现适用),并且引入新行为、更改所需行为或以其他方式修改需求。基于 OTEP 编写对应的 Specification(Spec)。Spec 规范描述了所有 OpenTelemetry 实现的跨语言要求和期望。基于 OTEP 实现各种语言相关 Profiling 数据采集和传输处理能力。
1. 发起 OTEP 与社区响应
由 Grafana 等公司起草的 Profile 领域数据模型提案经过 3 个多月的讨论和 review,已经在 3 月被社区通过进行了合并 #237、#239。这套标准定义的数据格式跟 pprof 比较接近。详细细节见相关PR。
目前社区对这个领域很看重,2024年3月,在官网通过Blog文章文档形式,介绍和宣布 Profilers 将作为OTel社区继 Traces/Metrics/Logs 后的重要组成部分。
2. 将 OTEP 集成到规范中
在完成 OTEP 的提交和社区合并以后,下一步需要在社区的 Spec 中添加相关 OTEP。目前这块 OTel-Profiles 小组是选择先确定提交 OpenTelemetry Protocol (OTLP) Specification #534,其作为 Spec 中的一部分,旨在描述数据在采集测、中间节点(例如收集器和后端)之间的编码、传输和传递机制。OTel-Profiles 小组希望先确定协议内容后,在 OTel-Collector 中进行基于相关数据传输协议标准的数据收集实现,以跑通整体流程。相关更多细节可以参见 Profiling SIG Meeting Notes。
3. 基于 OTEP 进行数据采集/收集测的实现
目前社区目前社区在相关部分的实现包括:
Splunk 已经针对 .Net 探针捐献了一个版本的实现,详情见#3196,相关代码已合并。
Elastic 向社区捐献一个基于 eBPF 实现的 Profiling 探针实现,详细讨论内容见#1918,该实现opentelemetry-ebpf-profiler已于6月份被社区接受,成为OTel社区第一个相关实现。
OTel Data Model 介绍
OTel Data Model是在Google pprof基础上设计而来,因此,本部分将介绍 pprof 相关基础内容,然后介绍OTel Data Model 相关 pprof 有哪些差异。
pprof简介
pprof 是 Go 语言内置的性能剖析工具,可以帮助分析 Go 程序的 CPU、内存、阻塞、和锁等维度的性能。
接下来,用一个例子来说明 pprof 的使用。比如下面的代码会对10万个数字进行排序,运行时间大概是接近4秒。
package main
import ( "fmt" "math/rand" "time")
func main() { start := time.Now().UnixMilli() arr := prepare(1000 * 100) doWork(arr) fmt.Println(time.Now().UnixMilli() - start)}
func prepare(n int) []int { arr := make([]int, n) for i := 1; i < n; i++ { arr[i] = rand.Intn(1000) } return arr}
func doWork(arr []int) { size := len(arr) if size == 0 { return }
for i := 0; i < size; i++ { for j := 0; j < size; j++ { if arr[i] < arr[j] { tmp := arr[i] arr[i] = arr[j] arr[j] = tmp } } }}如果想对代码进行优化,就可以使用pprof进行CPU热点剖析。程序运行结束后,会生成一个pprof格式的性能剖析文件/tmp/cpu.pprof。
package main
import ( "fmt" "math/rand" "os" "runtime/pprof" "time")
func main() { f1, err := os.Create("/tmp/cpu.pprof") if err != nil { fmt.Println(err) } pprof.StartCPUProfile(f1) start := time.Now().UnixMilli() arr := prepare(1024 * 200) doWork(arr) fmt.Println(time.Now().UnixMilli() - start) defer func() { pprof.StopCPUProfile() f1.Close() }()}
func prepare(n int) []int { arr := make([]int, n) for i := 1; i < n; i++ { arr[i] = rand.Intn(1000) } return arr}
func doWork(arr []int) { size := len(arr) if size == 0 { return }
for i := 0; i < size; i++ { for j := 0; j < size; j++ { if arr[i] < arr[j] { tmp := arr[i] arr[i] = arr[j] arr[j] = tmp } } }}可以用命令行对这个文件进行分析,找到占用CPU的热点方法。从下图可以看到,main.doWork方法占用了2800毫秒,也就是说大多数时间都消耗在这个方法上。
go tool pprof /tmp/cpu.pprofFile: ___go_build_golang_testType: cpuTime: May 30, 2024 at 7:32pm (CST)Duration: 3.94s, Total samples = 3.14s (79.78%)Entering interactive mode (type "help" for commands, "o" for options)(pprof) topShowing nodes accounting for 3140ms, 100% of 3140ms total flat flat% sum% cum cum% 2800ms 89.17% 89.17% 3140ms 100% main.doWork (inline) 340ms 10.83% 100% 340ms 10.83% runtime.asyncPreempt 0 0% 100% 3140ms 100% main.main 0 0% 100% 3140ms 100% runtime.main可以进一步分析,找出占用CPU的代码行。从下图可以看到,有1.67秒的时间在执行第42行,有990毫秒在执行第43行。结合代码,很容易看出,问题在于使用了冒泡排序,时间复杂度是N的平方。
(pprof) list main.doWorkTotal: 3.14sROUTINE ======================== main.doWork in /Users/yanglong/Documents/Private/code/go/golang-test/main.go 2.80s 3.14s (flat, cum) 100% of Total . . 35:func doWork(arr []int) { . . 36: size := len(arr) . . 37: if size == 0 { . . 38: return . . 39: } . . 40: . . 41: for i := 0; i < size; i++ { 1.67s 1.86s 42: for j := 0; j < size; j++ { 990ms 1.10s 43: if arr[i] < arr[j] { . . 44: tmp := arr[i] 140ms 180ms 45: arr[i] = arr[j] . . 46: arr[j] = tmp . . 47: } . . 48: } . . 49: } . . 50:}只需要更换更高效的排序算法,就应该会大大提升性能,运行时间从4秒缩短为了15毫秒左右。
package main
import ( "fmt" "math/rand" "os" "runtime/pprof" "sort" "time")
func main() { f1, err := os.Create("/tmp/cpu.pprof") if err != nil { fmt.Println(err) } pprof.StartCPUProfile(f1) start := time.Now().UnixMilli() arr := prepare(1024 * 100) doWork(arr) fmt.Println(time.Now().UnixMilli() - start) defer func() { pprof.StopCPUProfile() f1.Close() }()}
func prepare(n int) []int { arr := make([]int, n) for i := 1; i < n; i++ { arr[i] = rand.Intn(1000) } return arr}
func doWork(arr []int) { sort.Slice(arr, func(i, j int) bool { return arr[i] < arr[j] })}实际上,pprof 的 CPU 热点启动后,Go 会每隔10毫秒记录一次协程的方法栈,最终写入到 pprof 格式的文件中。下面对 pprof 格式做一些说明:

Profile
代表整个 pprof 文件,由多个 Sample 组成。
Sample
代表的是一次方法栈的快照。所谓方法栈,就是多个存在调用关系的方法,比如a() -> b() -> c()。
Label
在 Tracing 和 Profling 关联的场景,方法栈还有附加信息,比如当前的 TraceId 和 SpanId 等,这些信息则存储在 Label 中,结构有点像一个 map。
Location
pprof 在采样时,会记录c函数中正在执行的指令的地址,也对应的记录 b 和 a 函数的指令的地址。把上述的函数指令地址叫做 Location。
Mapping
实际上,不同的函数可能存在于不同的动态库中,为此也需要将动态库的文件名,动态库在内存中的地址范围等信息记录下来,把这些信息叫做 Mapping。
需要说明的是,由于编译器会对函数进行编译优化,比如内联等,一个 Location 可能表示多个函数及行号,所以 Location 和 Line 是1对多的关系。
也可以将 pprof 文件转换成火焰图,阅读起来会更加直观。

如果想对 pprof 有更多了解,可以阅读文章做更详尽了解。
pprof 和 OTel Format 对比
两种格式的核心功能都是记录 Sample(也就是方法栈),以及和 Sample 相关的附加信息。
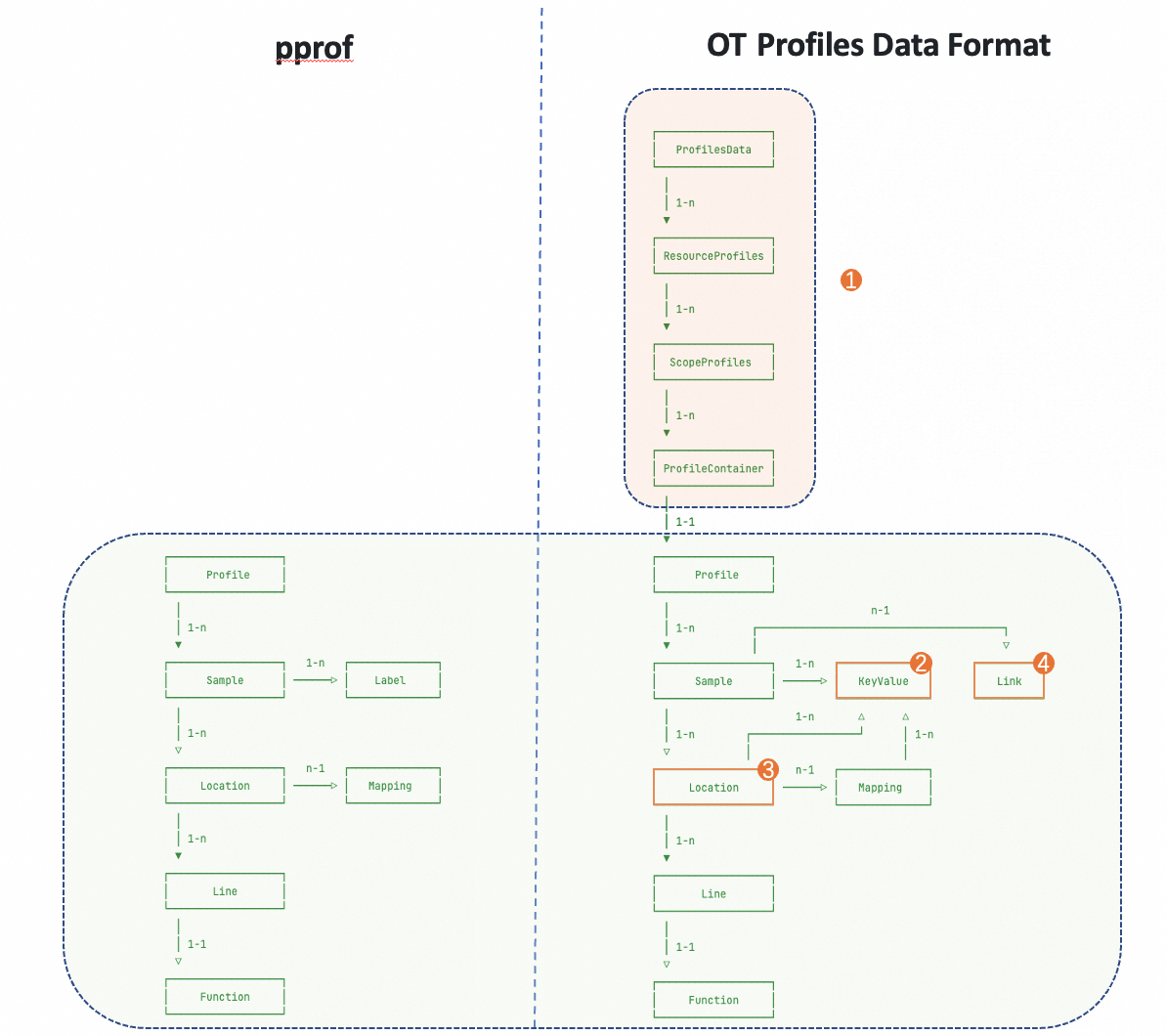
在上图中,左边是 pprof,右边是 OTel Format。通过对比可以看到,OTel Format 中保留了几乎所有 pprof的内容,也就是说 OTel Format 可以无损的转换为 pprof,但反过来则不行,因为 OTel Format 中增加了pprof 所没有的一些结构(上图中标记为1的部分)。
除此以为,OTel Format 对 pprof 也有一些优化
Label 的存储更加优化,可以节省更多空间,图中标记为2的部分
Location 的存储更加优化,可以节省更多空间,图中标记为3的部分
直接在每个样本中增加了和 Trace 关联的字段,以及时间字段,虽然 pprof 也能实现,但 OTel 的格式更加简单直接,图中标记为4的部分
还有一些其它的扩展点,比如可以将 JFR 文件的二进制数据直接保存到 OTel 的格式中,等等